HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis
ArXiv: arXiv:2009.01776
Authors
- Jiawei Chen (Microsoft STC Asia) t-jiawch@microsoft.com
- Xu Tan* (Microsoft Research) xuta@microsoft.com
- Jian Luan (Microsoft STC Asia) jianluan@microsoft.com
- Tao Qin (Microsoft Research) taoqin@microsoft.com
- Tie-Yan Liu (Microsoft Research) tyliu@microsoft.com
Abstract
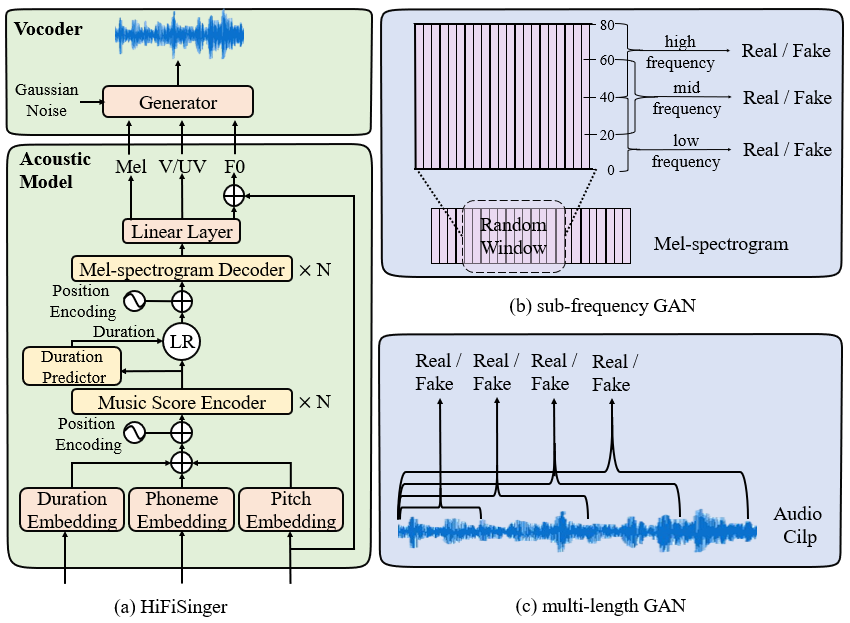
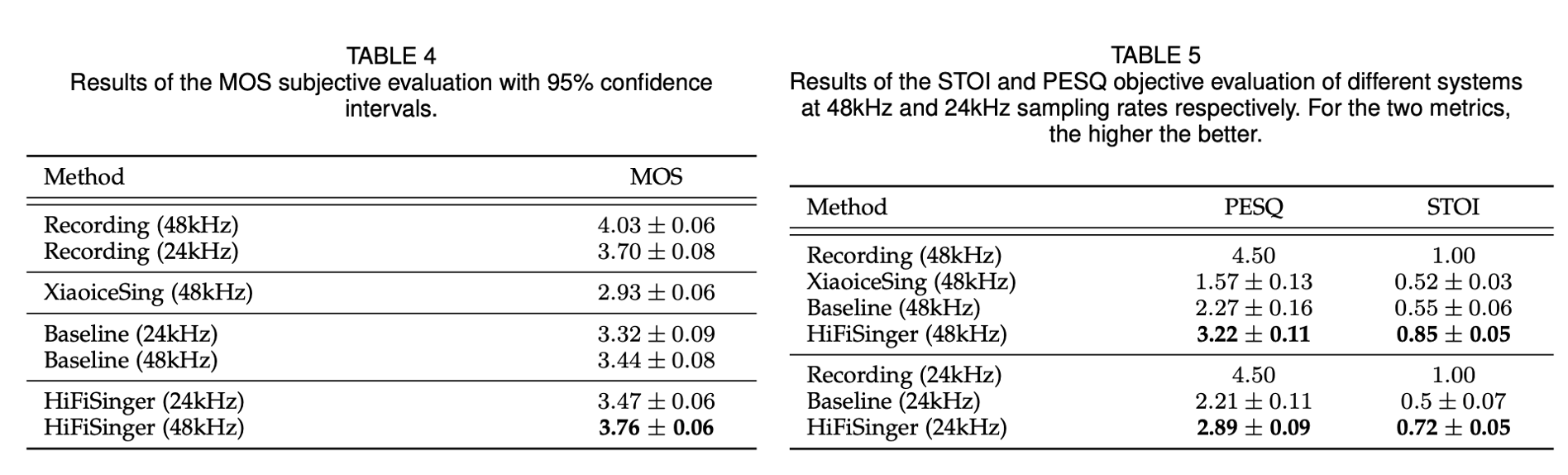
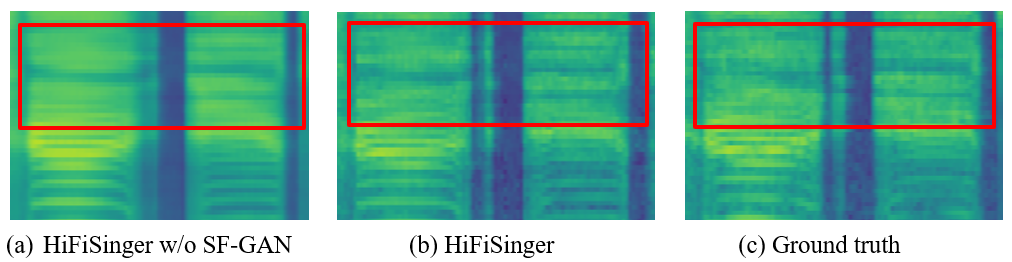
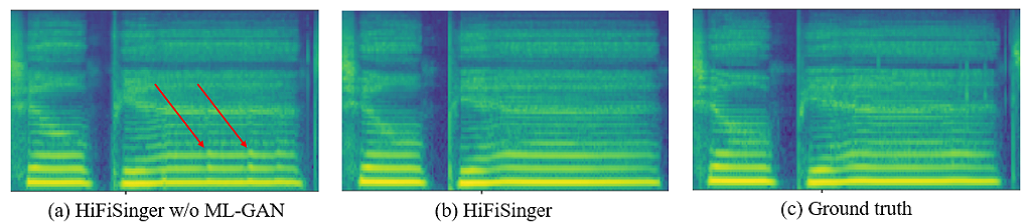
High-fidelity singing voices usually require higher sampling rate (e.g., 48kHz, compared with 16kHz or 24kHz in speaking voices) with large range of frequency to convey expression and emotion. However, higher sampling rate causes the wider frequency band and longer waveform sequences and throws challenges for singing modeling in both frequency and time domains in singing voice synthesis (SVS). Conventional SVS systems that adopt moderate sampling rate (e.g., 16kHz or 24kHz) cannot well address the above challenges. In this paper, we develop HiFiSinger, an SVS system towards high-fidelity singing voice using 48kHz sampling rate. HiFiSinger consists of a FastSpeech based neural acoustic model and a Parallel WaveGAN based neural vocoder to ensure fast training and inference and also high voice quality. To tackle the difficulty of singing modeling caused by high sampling rate (wider frequency band and longer waveform), we introduce multi-scale adversarial training in both the acoustic model and vocoder to improve singing modeling. Specifically, 1) To handle the larger range of frequencies caused by higher sampling rate (e.g., 48kHz vs. 24kHz), we propose a novel sub-frequency GAN (SF-GAN) on mel-spectrogram generation, which splits the full 80-dimensional mel-frequency into multiple sub-bands (e.g. low, middle and high frequency bands) and models each sub-band with a separate discriminator. 2) To model longer waveform sequences caused by higher sampling rate, we propose a multi-length GAN (ML-GAN) for waveform generation to model different lengths of waveform sequences with separate discriminators. 3) We also introduce several additional designs and findings in HiFiSinger that are crucial for high-fidelity voices, such as adding F0 (pitch) and V/UV (voiced/unvoiced flag) as acoustic features, choosing an appropriate window/hop size for mel-spectrogram, and increasing the receptive field in vocoder for long vowel modeling in singing voices. Experiment results show that HiFiSinger synthesizes high-fidelity singing voices with much higher quality: 0.32⁄0.44 MOS gain over 48kHz/24kHz baseline and 0.83 MOS gain over previous SVS systems. Audio samples are available at https://speechresearch.github.io/hifisinger.
Contents
Audio Samples1.1 Audio Quality
Ablation Studies
2.1 SF-GAN
2.2 ML-GAN
2.3 Pitch input
2.4 Window/hop size
2.5 Pitch Control
2.6 Duration control
Audio Samples
48kHz sampling rate is used unless otherwise stated.
Audio Quality
这么说来很不单纯,你陪我看海
| Recording (48kHz) | Baseline (24kHz up) | XiaoiceSing (48kHz) | HiFiSinger (48kHz) |
|---|---|---|---|
| Recording (24kHz) | Baseline (24kHz) | Baseline (48kHz) | HiFiSinger (24kHz) |
|---|---|---|---|
宁静的夏天,天空中繁星点点
| Recording (48kHz) | Baseline (24kHz up) | XiaoiceSing (48kHz) | HiFiSinger (48kHz) |
|---|---|---|---|
| Recording (24kHz) | Baseline (24kHz) | Baseline (48kHz) | HiFiSinger (24kHz) |
|---|---|---|---|
坏的是我发现不知不觉不见到你不是很习惯
| Recording (48kHz) | Baseline (24kHz up) | XiaoiceSing (48kHz) | HiFiSinger (48kHz) |
|---|---|---|---|
| Recording (24kHz) | Baseline (24kHz) | Baseline (48kHz) | HiFiSinger (24kHz) |
|---|---|---|---|
Ablation Studies
SF-GAN
这么说来很不单纯,你陪我看海
| HiFiSinger | HiFiSinger with 0 SF-GAN | HiFiSinger with 1 SF-GAN | HiFiSinger with 5 SF-GAN |
|---|---|---|---|
遇见一个人然后生命全改变,原来不是恋爱才有的情节
| HiFiSinger | HiFiSinger with 0 SF-GAN | HiFiSinger with 1 SF-GAN | HiFiSinger with 5 SF-GAN |
|---|---|---|---|
我的小鬼小鬼,逗逗你的眉眼,让你喜欢这世界
| HiFiSinger | HiFiSinger with 0 SF-GAN | HiFiSinger with 1 SF-GAN | HiFiSinger with 5 SF-GAN |
|---|---|---|---|
ML-GAN
谁在最需要的时候轻轻拍着我肩膀
| HiFiSinger | HiFiSinger without ML-GAN |
|---|---|
见证你成长让我感到充满力量
| HiFiSinger | HiFiSinger without ML-GAN |
|---|---|
你知道它的花语签上名,我继续一个人远行
| HiFiSinger | HiFiSinger without ML-GAN |
|---|---|
Pitch and Voiced/Unvoiced input
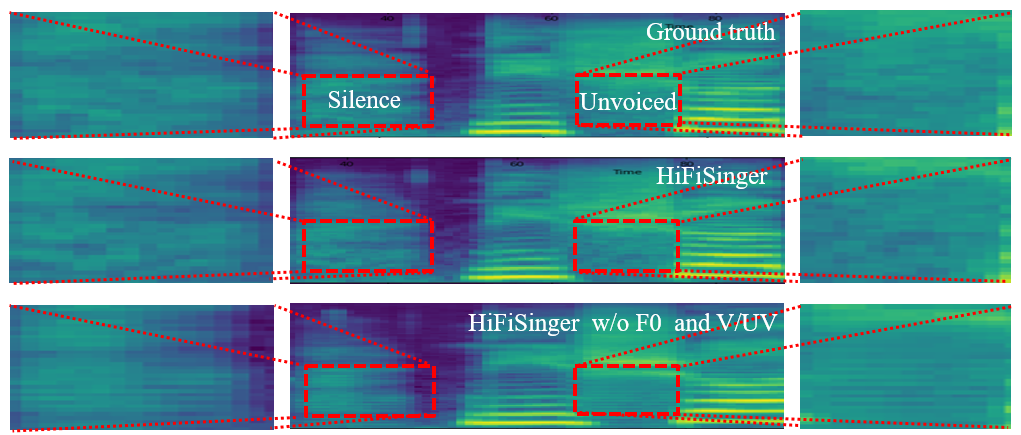
这么说来很不单纯,你陪我看海
| HiFiSinger | HiFiSinger without F0 and V/UV input |
|---|---|
遇见一个人然后生命全改变,原来不是恋爱才有的情节
| HiFiSinger | HiFiSinger without F0 and V/UV input |
|---|---|
我的小鬼小鬼,逗逗你的眉眼,让你喜欢这世界
| HiFiSinger | HiFiSinger without F0 and V/UV input |
|---|---|
window/hop size
这么说来很不单纯,你陪我看海
| HiFiSinger | HiFiSinger with 12ms window | HiFiSinger with 50ms window |
|---|---|---|
遇见一个人然后生命全改变,原来不是恋爱才有的情节
| HiFiSinger | HiFiSinger with 12ms window | HiFiSinger with 50ms window |
|---|---|---|
我的小鬼小鬼,逗逗你的眉眼,让你喜欢这世界
| HiFiSinger | HiFiSinger with 12ms window | HiFiSinger with 50ms window |
|---|---|---|
Pitch Control

左心房,暖暖的好饱满
| Normal scale | Down 4 semitones | Up 4 semitones |
|---|---|---|
我想说其实你很好,你自己却不知道
| Normal scale | Down 4 semitones | Up 4 semitones |
|---|---|---|
在朋友里面就数你最特别,总让我觉得很亲很铁
| Normal scale | Down 4 semitones | Up 4 semitones |
|---|---|---|
Duration Control

因为我,完全信任你
| 0.75x Speed | 1.00x Speed | 1.25x Speed |
|---|---|---|
我想说其实你很好,你自己却不知道
| 0.75x Speed | 1.00x Speed | 1.25x Speed |
|---|---|---|
杜鹃啼血声,芙蓉花蜀国尽缤纷
| 0.75x Speed | 1.00x Speed | 1.25x Speed |
|---|---|---|
Our Related Works
Almost Unsupervised Text to Speech and Automatic Speech Recognition
FastSpeech: Fast, Robust and Controllable Text to Speech
Semi-Supervised Neural Architecture Search
MultiSpeech: Multi-Speaker Text to Speech with Transformer
DeepSinger: Singing Voice Synthesis with Data Mined From the Web
FastSpeech 2: Fast and High-Quality End-to-End Text-to-Speech
UWSpeech: Speech to Speech Translation for Unwritten Languages
LRSpeech: Extremely Low-Resource Speech Synthesis and Recognition
Denoising Text to Speech with Frame-Level Noise Modeling